Schema Inspection
What's this?
Schema inspection is the foundation that Metamapper was built on. Once you have connected your datastore(s), we scan and inspect your database schema for any changes so that we can keep your data catalog up to date.
Core Concepts
Before you dig too deeply into Metamapper, it's helpful to be familiar with a few standard database concepts and object types.
These objects represent different data assets that Metamapper allows you to track, search, and annotate.
Datastores
A datastore is an organized collection of data. It is the highest level concept in Metamapper when it comes to data assets.
It is common for an organization to centralize their analytics using a data warehouse. This provides a single source of truth for all analytics around the company. Example data warehouses include Snowflake and AWS Redshift.
Other organizations use multiple, smaller MySQL databases, where each database contains data specific to a business area. For example, you have one database for your marketing department, but a different database for your finance department. This is commonly known as a data mart strategy.
These are all examples of datastores that Metamapper can catalog.
Tables
Databases consist of a series of tables (sometimes refered to as collections). A table contains one or more columns and one or more rows.
For example, in a table that represents companies, each row would represent a single company. Columns might represent things like company name, number of employees, headquarters location, and so on.
Here’s an example of that table:
| company_name | hq_city | hq_state | employee_count |
|---|---|---|---|
| General Motors | Detroit | MI | 48,012 |
| Ford | Dearborn Heights | MI | 71,884 |
| Tesla | Palo Alto | CA | 23,127 |
Columns
Tables have a consistent structured that is defined in the form of columns. Each column is given a series of attributes to limit the type and format of the data that can be stored within it. In other words, all the cells in a column must contain the same type of information.
Here are some common data types:
Strings (
text,char,varchar, etc.) - Snippets of text are commonly referred to as strings. These fields are used to store things like names, emails, or anyhting else that is plaintext.Numerics (
decimal,integer,float, etc.) - These fields store numbers of varying sizes and precision. For example, you would probably use a integer to store data like age since it has no precision, but a decimal to store financial numbers.Timestamps (
timestamp,date,datetime, etc.) – These fields are used to store dates and times (or both), called "timestamps". This allows you to filter data based on date ranges and other temporal attributes.
Data types and other metadata, such as maximum length, if the field can be null, etc. can be helpful clues to users on what the data is and how it can be used. For example, if a user needed to find the price of a product, it would make sense to filter your search to only numeric columns.
Indexes
Indexes are used to quickly locate data without having to search every row in a database table every time a database table is accessed. Indexes are commonly added to a database to improve querying performance.
Indexes are a fairly technical concept, so they will probably not be relevant for most business users. But Metamapper still indexes them (pun intended) into the data catalog.
Schemas
Tables and indexes are generally namespaced under what is called a schema. This is commonly used as a way to organize your data.
For example, the data used to power your web application might be under the app schema while your internal employee data might be under the employees schema.
The information_schema schema
So now we know what types of data assets exist. But how do we know what assets exist in our datastore?
I'm glad you asked. Database maintain a set of internal tables that contain metadata about the data stored within said database. These system tables are often found in the information_schema or sys namespace, depending on the database provider.
Let's take this query, for example:
SELECT table_schema, table_name, column_name, data_type
FROM information_schema.columns
LIMIT 6
If we run this query against a Postgres database, it would return something like this:
| table_schema | table_name | column_name | data_type |
|---|---|---|---|
| public | django_migrations | id | integer |
| public | django_migrations | app | character varying |
| public | django_migrations | applied | timestamp |
| app | version | version | character varying |
| app | widgets | id | integer |
| app | widgets | name | character varying |
This is data about our data! That's super meta. System tables exists for tables, columns, indices, functions, table relationships – pretty much any database object you can think of.
Metamapper uses a database-agnostic API to periodically runs queries against these system tables, which is how it keeps your data catalog up to date.
Detecting schema changes
One useful feature of Metamapper is the ability to track when Data Definition Language (DDL) statements are executed. In short, we record when a database object is created, altered, or dropped between subsequent syncs.
We call this schema change detection. Most datastores that we support have the concept of an object identifier. This is a primary key that is added to a database object, such as a table or column, when it is created. It is a consistent identity for every database object we sync, so we can tell on subsequent syncs when something has changed.
This feature can be especially helpful for data engineering teams where an upstream team might not communicate a schema modification that breaks downstream data systems.
Note that there are instances where an object identity is not reliable. MySQL, for example, does not retain object identities for columns. Instead, we opt to use the human-readable name of the database object (e.g., the column name) as the object identity.
Datastore sync and analysis
Metamapper syncs your datastores on an hourly basis. Once the sync is complete, the data catalog for each datastore is viewable by going to the Datastore > Data Assets page.
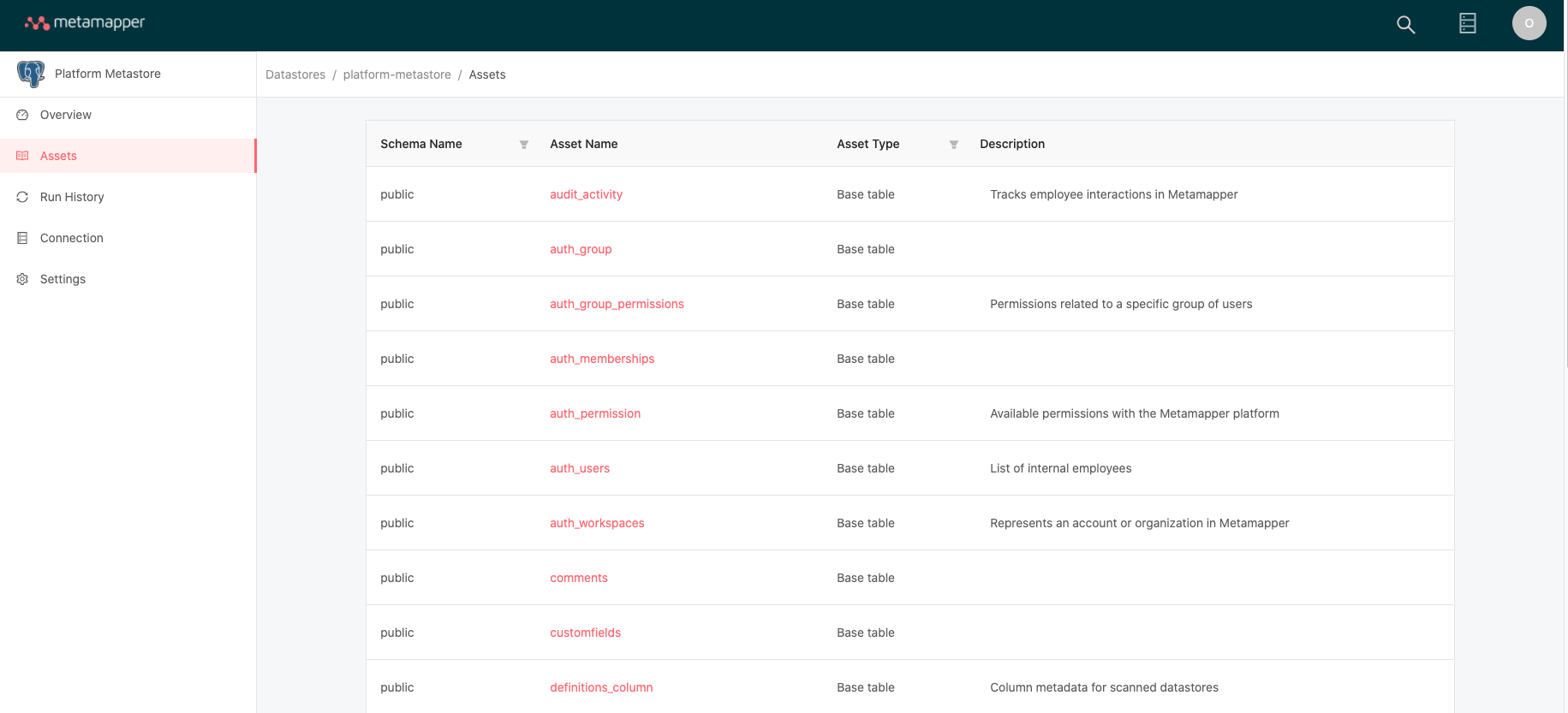
Using object identities, metadata that you add via annotations, custom properties, and other mechanisms will be retained between syncs.
Search is a powerful way to find data assets. Check out the Search section for more details.
Monitoring
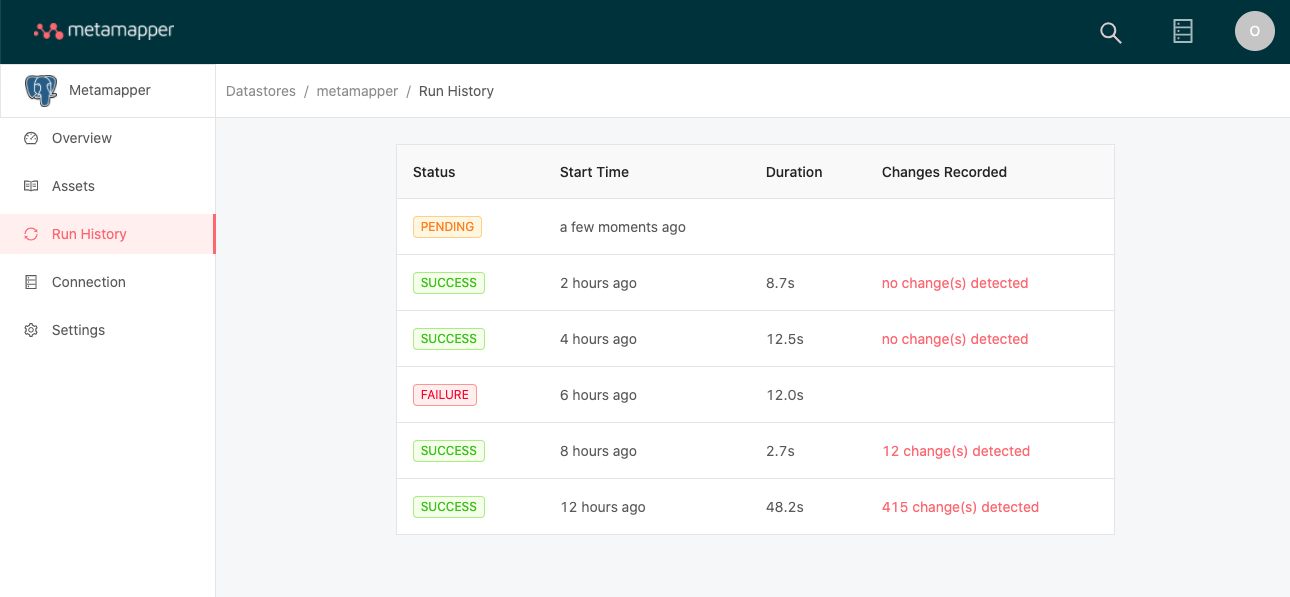
With each run, there is a risk that it might fail for some reason, such as a dropped connection. We have certain fault tolerance mechanisms in place, such as retries, but some errors are unrecoverable.
You can view the status of the past syncs from the Run History page of each datastore. Status can be pending, success, or failure. When a run fails, you can hover over the status badge to see a brief message describing the error that caused the run to rail.
If you installed Metamapper via the official bootstrap, you should also be able to view the logs generated by Docker to help with debugging.
Our processes are idempotent by design, which means that we'll catch up without issue on the next run – assuming we are able to connect and the error does not persist.